Lecture 4.3: Token-Efficient Tool Design
Module 4, Lecture 4.3 | Section 2: Working with LLMs in Practice
Overview
Lectures 4.1 and 4.2 established a reactive approach to context management: measure context growth, then apply strategies — sliding window, selective preservation, compaction — when the budget threshold is crossed. This lecture is about prevention. Tool design is the single biggest lever for controlling context size, and it operates proactively rather than after the fact.
The key principle: every tool result enters the conversation history and stays there for every subsequent API call. A file read on step 3 is still in context on step 30. If that file was 500 lines, those 500 lines — roughly 2,000 tokens — are re-sent with every subsequent API call for the rest of the session.
Why Tool Design Matters
When tool-calling emerged as a core capability, the first generation of agent tools were often adapted from existing REST APIs and developer interfaces. These were designed for humans: return everything, let the caller decide what to use. That design philosophy is the wrong fit for LLM agents.
The difference is fundamental. A human developer calling a REST API reads the response, extracts what they need, and discards the rest. An LLM agent cannot discard anything — every tool result becomes part of the conversation context and is re-sent on every subsequent API call. A verbose tool that was designed to be convenient for humans becomes an expensive liability for an agent.
Three properties make tool results especially costly in agentic contexts:
- Append-only — once a result is in context, it stays until explicitly managed
- Cumulative — the agent may call the same tool multiple times; each result accumulates
- Proportional cost — a 2,000-token tool result multiplies across every future API call in the session
Tool results account for 50–70% of tokens in a typical agent session (established in Lecture 4.1). That means tool design is the most impactful variable under the agent engineer's control — more impactful than system prompt length, more impactful than response verbosity.
The Core Problem: Naive Tool Design
Consider a standard read_file tool:
# Naive design — returns the entire file
def read_file(path):
return open(path).read()
# A 500-line file → ~2,000 tokens in context
When an agent calls read_file("parser.py"), it gets the entire file. If the agent was only trying to find references to a specific column name, it received 490 lines of irrelevant content along with the 10 it needed.
Scale this across a realistic session: three files read, two reads each, plus some log files — the context can accumulate 12,000+ tokens of raw file content within the first handful of agent steps. Most of those tokens are never referenced again, but they remain in every subsequent API call.
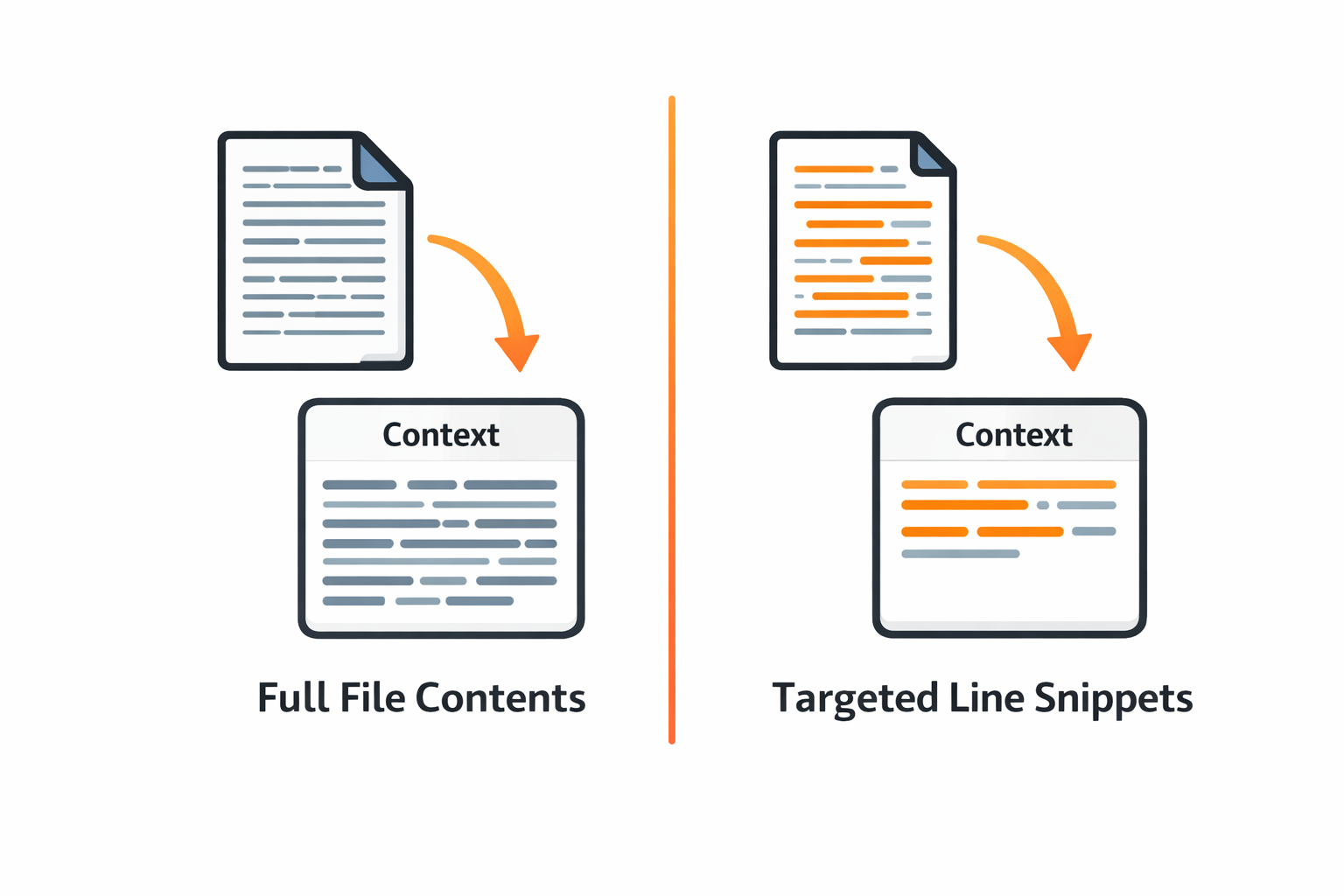
Progressive Disclosure: The Core Pattern
The solution is to split one verbose tool into two focused tools that let the agent ask for exactly what it needs.
# Tool 1: search_file — returns matching line numbers and snippets
def search_file(path, query):
matches = []
for i, line in enumerate(open(path), 1):
if query in line:
matches.append(f"Line {i}: {line.strip()}")
return "\n".join(matches)
# Returns 5 matches → ~50 tokens
# Tool 2: read_lines — returns a specific line range
def read_lines(path, start, end):
lines = open(path).readlines()
return "".join(lines[start-1:end])
# Returns 20 lines → ~80 tokens
With these two tools, the agent workflow becomes:
- Call
search_file("parser.py", "password_hash")— receives line numbers and snippets (~50 tokens) - Call
read_lines("parser.py", 12, 18)— receives the specific code section (~80 tokens)
Total: ~130 tokens, versus the ~2,000 tokens of the naive read_file. The agent no longer has access to read_file at all — the tool design forces it to be precise about what it needs.
This pattern is called progressive disclosure: reveal information in layers, with detailed content available on demand after the agent has identified what it needs.

The pattern generalizes beyond file reading:
| Domain | Metadata tool | Content-on-demand tool |
|---|---|---|
| Files | search_file(path, query) → line numbers |
read_lines(path, start, end) |
| Database | describe_table(table) → columns + row count |
query_rows(table, filter, limit) |
| API | search_records(query) → IDs + titles |
get_record(id) |
| Filesystem | list_directory(path) → names + sizes |
read_file(path, start, end) |
In each case: return metadata first, let the agent decide what specific content to request.
This is also closely related to the Unix philosophy of small, orthogonal tools with well-defined purposes. Good tool design for agents and good tool design in general share the same principles — do one thing well, avoid side effects, return only what was asked for.
Pagination
When a tool could return hundreds or thousands of results, return a fixed page instead:
# search_codebase(query, page=1, per_page=10)
# Returns 10 results at a time — not all 200
The agent receives the first page and decides whether it needs more. In practice, the answer is usually in the first few results. If the agent needs subsequent pages, it makes another call — adding only the next 10 results to context, not all 200 at once.
Pagination is the correct design for any search or listing tool. Returning unbounded results — "find all files matching *.py" on a large codebase — is a single tool call that can consume thousands of tokens and provide no more value than returning the first ten matches.
Summarized Results
Return a verdict instead of raw output:
# run_tests() → summarized result
# "8 passed, 2 failed: test_auth_login, test_auth_refresh"
# Not: 200 lines of test output
The agent needs to know whether tests passed or failed. It does not need the complete output of every passing test. If it needs detail on a specific failure, it can call a separate tool: get_test_output("test_auth_login").
This applies broadly:
- Test runners: pass/fail counts and failure names, not full output
- Log analysis: error counts and error types, not full log contents
- Compilation output: success/failure and error messages, not the full build log
- Database queries: aggregated statistics before raw rows
The pattern is the same as progressive disclosure — give the agent enough to make its next decision, and let it request detail only when needed.
Practical Implications
More tool calls, smaller context. Splitting read_file into search_file + read_lines means the agent makes two calls instead of one. But each call carries a smaller result, and the total context footprint is a fraction of the naive approach. The apparent overhead of extra API calls is generally offset by lower cost and better quality on all subsequent calls.
Tool descriptions guide behavior. When you define search_file and read_lines as the available tools, the LLM naturally uses the search-then-read pattern. The tool definitions constrain what the agent can ask for. A tool named read_file that returns entire files invites verbose reads; a tool named read_lines with start/end parameters invites precise reads. Tool design shapes agent behavior.
Rule-based summarization is usually sufficient. Summarizing test output, formatting line numbers from search results, returning row counts from database queries — these can be done with simple logic, not an extra LLM call. The LLM-based compaction from Lecture 4.2 is for compacting the full conversation; tool-level summarization is a straightforward engineering task.
Key Takeaways
- Tool results are the biggest context lever — 50–70% of tokens, and tool design is entirely under the engineer's control.
- Progressive disclosure — metadata first, specific content on demand. Split broad tools into focused tools that return less by default.
- Pagination and summarization — return the minimum the model needs to make its next decision. Detailed results are available on demand.